
DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
[Project-page] [arXiv] [Code] [Paper]
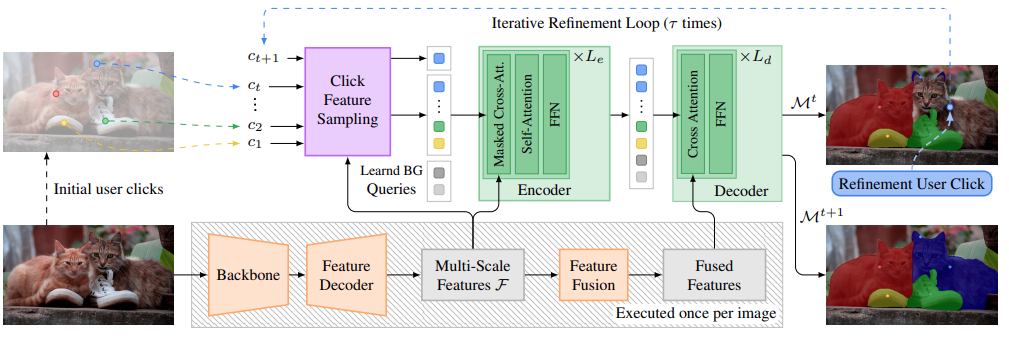 Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of- the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of- the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
 Video frames generation is a challenging task due to the wide uncertainty in the nature of the problem. In this lab project, we approach the task of the video prediction using the model discussed in the lab, based on the Video Ladder Network. In our work, the moving Moving MNIST (MMNIST) and the KTH Action dataset are being used to perform the experiments. We present the effects of various design choices in the model architectures and the training settings. The final results achieved on both datasets are realistic and coherent with the given context frames, indicating the strong learning capability of the network.
Video frames generation is a challenging task due to the wide uncertainty in the nature of the problem. In this lab project, we approach the task of the video prediction using the model discussed in the lab, based on the Video Ladder Network. In our work, the moving Moving MNIST (MMNIST) and the KTH Action dataset are being used to perform the experiments. We present the effects of various design choices in the model architectures and the training settings. The final results achieved on both datasets are realistic and coherent with the given context frames, indicating the strong learning capability of the network.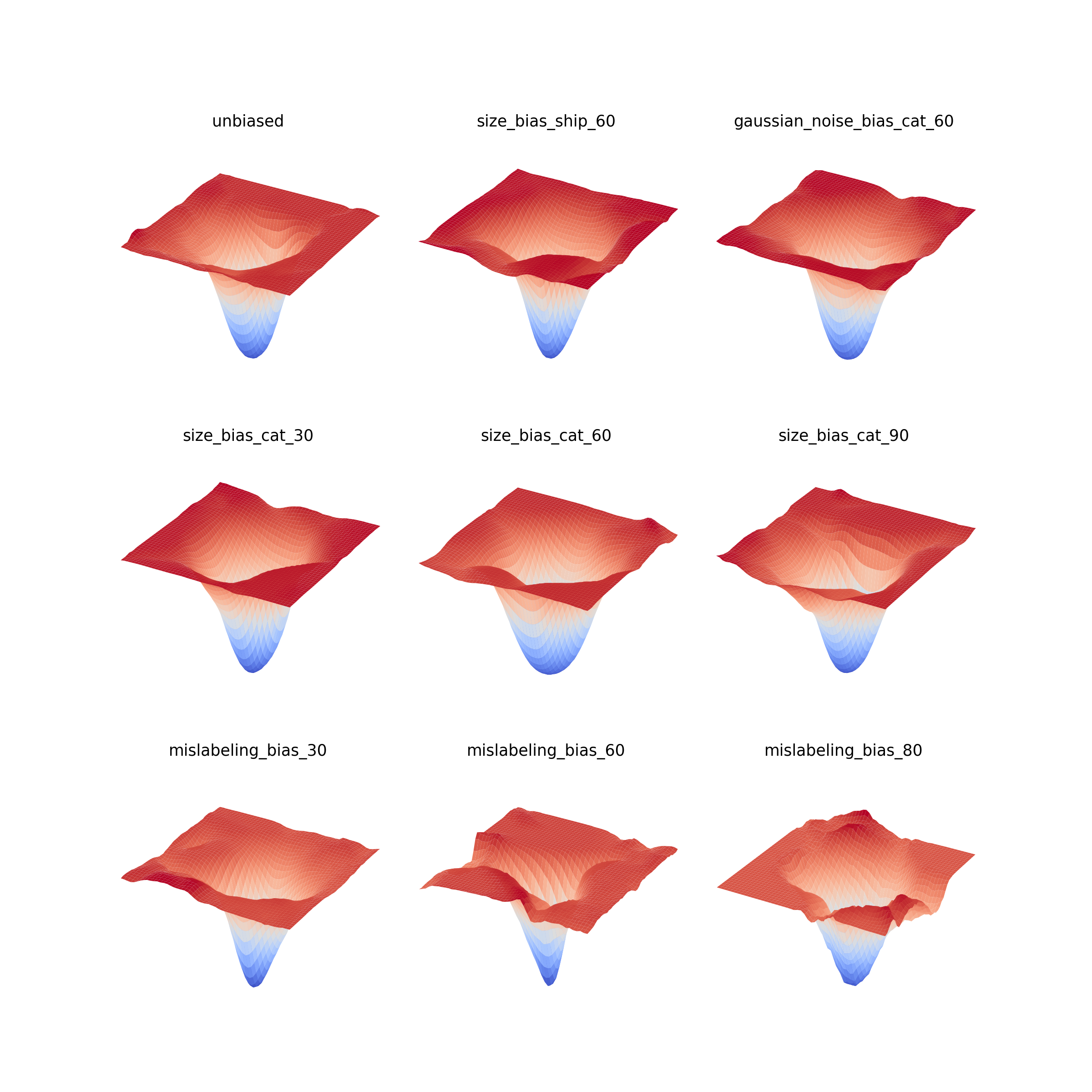 Many studies show a positive correlation between the generalization ability of a deep neural network and the flatness of the minima in its loss landscape. Inspired by this statement, many studies investigate the effect of using different training pa- rameters and network architecture on the loss landscape of the neural network. This study investigates the effect of training a deep neural network on a biased dataset on its loss landscape by visualizing the loss landscape of the trained model. We found that different types of biases in the training dataset can affect the geometry of the loss landscape around the minima.
Many studies show a positive correlation between the generalization ability of a deep neural network and the flatness of the minima in its loss landscape. Inspired by this statement, many studies investigate the effect of using different training pa- rameters and network architecture on the loss landscape of the neural network. This study investigates the effect of training a deep neural network on a biased dataset on its loss landscape by visualizing the loss landscape of the trained model. We found that different types of biases in the training dataset can affect the geometry of the loss landscape around the minima.